Computer Vision (CV) ist ein Teilbereich der künstlichen Intelligenz, mit dem Computer visuelle Daten (z. B. Bilder oder Videos) analysieren, interpretieren und darauf basierend automatisierte Entscheidungen oder Klassifikationen treffen können. Durch moderne Verfahren des maschinellen Lernens und Deep Learning kann CV Objekte, Szenen und Muster erkennen und klassifizieren — z. B. Personen, Tiere, Gegenstände oder Umgebungen.
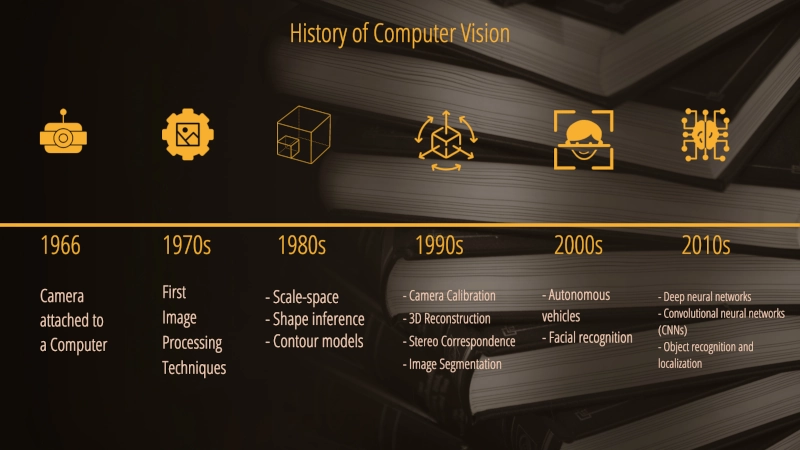
Die Wurzeln der Computer Vision reichen bis in die 1960er Jahre zurück, als erste Experimente mit der digitalen Bilderverarbeitung begannen. Über Jahrzehnte wurden Techniken wie Kanten‑ und Linienerkennung, Segmentierung, 3D‑Rekonstruktion und Bewegungsschätzung entwickelt. Mit dem Aufkommen leistungsfähiger Hardware, großen Datensätzen und neuronaler Netze seit den 2000er Jahren erfuhr Computer Vision einen massiven Fortschritt — heute ist CV eine zentrale Technologie in vielen Bereichen, von Medizin bis Industrie.
Die Computer Vision bleibt eine dynamische Disziplin — mit laufender Forschung, neuen Methoden und wachsender Bedeutung.
In der heutigen KI‑gestützten Welt spielt Computer Vision eine zentrale Rolle: Dank Fortschritten im Deep Learning können CV‑Systeme Bilder und Videos automatisch analysieren — von Objekterkennung über Segmentierung bis hin zu Szenenverständnis. Durch große Datenmengen und Rechenleistung steigen Genauigkeit und Einsatzmöglichkeiten stark.

Typische Schritte im Computer Vision Prozess sind:
Trotz großer Fortschritte stehen Computer‑Vision‑Systeme weiterhin vor Herausforderungen: Qualität der Bilder, Beleuchtung, Perspektiven, Verdeckung, Unterschiedlichkeit der Szenen oder geringe Trainingsdatenqualität können die Genauigkeit beeinträchtigen. Zudem sind robuste Trainingsdaten und gute Modelle nötig, um zuverlässige Ergebnisse zu erzielen.
Tipp:
Für die Entwicklung zuverlässiger Computer-Vision-Modelle sind qualitativ hochwertige, annotierte Bild- und Videodaten essenziell. clickworker bietet maßgeschneiderte Trainingsdatensätze für unterschiedlichste Computer-Vision-Anwendungen – skalierbar, präzise und individuell auf Ihre Anforderungen abgestimmt.
KI-Trainingsdaten von clickworker
CV ermöglicht Automatisierung visueller Aufgaben, analysiert große Bild‑ oder Videomengen schnell und effizient, bietet hohe Konsistenz bei Erkennung und Klassifikation und lässt sich auf viele Einsatzbereiche skalieren — von Bildern bis zu großen Medienbeständen oder Echtzeit‑Streams.
Computer Vision wird in vielen Bereichen genutzt — z. B. für Gesichtserkennung, Objekterkennung, Szenen‑ und Bilderkennung, medizinische Bildanalyse, Qualitätskontrolle, autonome Systeme, Sicherheits‑ und Überwachungssysteme, AR/VR‑Anwendungen und vieles mehr.
Branchen wie Gesundheit, Industrie, Mobilität, Sicherheit, Einzelhandel, Landwirtschaft, Forschung und Technologie setzen Computer Vision ein — sowohl in großen Unternehmen als auch Startups. CV hilft, Prozesse zu automatisieren, Kosten zu senken und neue Technologien bzw. Dienste zu ermöglichen.
Für Projekte mit Computer Vision gibt es eine breite Auswahl an Bibliotheken, Open‑Source‑Lösungen und Plattformen — geeignet für Objekterkennung, Segmentierung, Klassifikation oder Bild‑ und Videoanalyse. In Verbindung mit guten Trainingsdaten lassen sich robuste CV‑Lösungen realisieren.
Computer Vision entwickelt sich weiter — mit multimodalen Ansätzen (Bild + Sensorik + KI), besserer Generalisierung, Echtzeit‑Verarbeitung, Deep Learning Fortschritten und breiterer Integration in Medizin, Mobilität, Smart Systems, Smart Cities, Industrie 4.0 und Alltagstechnologien.
Computer Vision bleibt ein Schlüsselbereich der künstlichen Intelligenz: Sie erlaubt Maschinen, visuelle Daten zu interpretieren und daraus Entscheidungen oder Aktionen abzuleiten. Mit leistungsfähiger Hardware, guten Trainingsdaten und skalierbaren Systemen eröffnet CV viele Möglichkeiten — von Innovation bis Automatisierung. Damit das Potenzial ausgeschöpft wird, sind aber weiterhin Forschung, verantwortungsbewusster Einsatz und bewusste Datenqualität entscheidend.
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz, bei dem Systeme Muster aus Daten lernen, ohne explizit programmiert zu werden. In der Computer Vision werden vor allem Deep‑Learning‑Modelle eingesetzt, um Objekte, Szenen oder Strukturen automatisch aus Bildern und Videos zu erkennen.
Neben klassischen Bildverarbeitungsalgorithmen kommen heute überwiegend Deep‑Learning‑Modelle wie Convolutional Neural Networks (CNNs), Vision Transformers (ViT), Segmentierungsmodelle (z. B. U‑Net) und Multi‑Modal‑Modelle zum Einsatz. Diese Systeme können Merkmale selbstständig lernen und bieten deutlich bessere Genauigkeit als frühere Ansätze.
Neben Bildern und Videos werden zunehmend auch 3D‑Daten wie Tiefenkarten, LiDAR‑Scans und Punktwolken genutzt. Diese Datenformen ermöglichen präzisere Raumwahrnehmung, Objekterkennung und Navigation, beispielsweise in Robotik und autonomen Fahrzeugen.
Computer Vision automatisiert visuelle Prozesse, erhöht Effizienz, Geschwindigkeit und Genauigkeit und liefert Einblicke, die manuell kaum erreichbar wären. Unternehmen nutzen CV für Qualitätskontrolle, Sicherheit, Inventur, Schadenserkennung, Prozessoptimierung, Kundenanalyse und viele weitere Anwendungen.
Computer Vision kann personenbezogene Daten wie Gesichter, Bewegungen oder Verhaltensmuster verarbeiten. Risiken bestehen u. a. bei Überwachung, ungewollter Identifizierung, Bias in Modellen sowie regulatorischen Anforderungen (z. B. DSGVO). Transparente Datennutzung, sichere Speicherung und verantwortungsvolle Anwendung sind daher essenziell.
Von den ersten experimentellen Bildverarbeitungsmethoden der 1960er entwickelte sich CV über klassische Edge‑Detection‑ und Segmentierungsverfahren hin zu modernen Deep‑Learning‑Modellen. Heute erreichen CV‑Systeme oft übermenschliche Genauigkeit in Aufgaben wie Objekterkennung, medizinischer Bildanalyse oder autonomer Navigation.
Computer Vision Processing umfasst die gesamte Pipeline der visuellen Analyse: Datenerfassung, Vorverarbeitung, Merkmalsextraktion, Modellinferenzen und Interpretation der Ergebnisse. Ziel ist es, visuelle Informationen automatisch zu analysieren und darauf basierend Entscheidungen abzuleiten.
Herausfordernd wird CV bei schlechten Lichtverhältnissen, unscharfen Bildern, Bewegungsunschärfe, Wettereffekten, verdeckten Objekten, ungewohnten Winkeln oder stark veränderten Umgebungen. Auch mangelhaft annotierte oder zu kleine Trainingsdatensätze können zu Fehlklassifikationen führen.
Für leistungsfähige Modelle – insbesondere für Objekterkennung und Segmentierung – sind große, vielfältige und gut annotierte Datensätze entscheidend. Neuere Ansätze wie Transfer Learning, Synthetic Data und Foundation Models können den Bedarf reduzieren, ersetzen jedoch hochwertige Trainingsdaten nicht vollständig.


