
Datenbanken sind heute ein entscheidendes Element im maschinellen Lernen (ML). Mit ihrer Hilfe können Sie verschiedene Modelle für maschinelles Lernen und künstliche Intelligenz (KI) trainieren. Die herausragenden Vorteile, die diese Technologien bieten, sind der Hauptgrund für ihren zunehmenden Einsatz.
Die Vielzahl neuer Datensätze, die in den vergangenen Jahrzehnten entstanden sind, macht die Suche nach dem optimalen Datensatz für individuelle Anforderungen zu einer Herausforderung. Gleichzeitig bietet diese Vielfalt den Unternehmen die Möglichkeit, aus einem breiten Spektrum an Datensätzen genau diejenigen auszuwählen, die perfekt zu ihren Anwendungsplänen passen.
Welche sind also die besten Datenbanken für maschinelles Lernen auf dem Markt? Ist eine kostenlose oder eine maßgeschneiderte KI-Datenbank die bessere Wahl? Und welche Vorteile bieten benutzerdefinierte Datenbanken für Ihre ML-Aufgaben? Diese Fragen werden wir in diesem Artikel erörtern.
Die richtige Wahl von Datenbanken im Bereich des maschinellen Lernens und der künstlichen Intelligenz ist entscheidend für den Erfolg Ihrer Projekte. Wir haben die zehn besten Datenbanken und ihre Schlüsselfunktionen aufgelistet, um Ihnen die Entscheidung zu erleichtern. Wählen Sie diejenige aus, die am besten Ihren Anforderungen entspricht.
Redis ist eine erstklassige Open-Source-In-Memory-Datenbank, die derzeit von vielen auf dem Markt verwendet wird. Sie eignet sich ideal als Datenbank für Projekte und Aufgaben im Bereich maschinelles Lernen und Künstliche Intelligenz.
Das Beste an Redis ist, dass es verschiedene Datenstrukturen wie bitmaps, geospatial indexes, sorted sets, etc. unterstützt. Darüber hinaus können Sie folgende Funktionen nutzen, wenn Sie Redis als Datenbank wählen:
Zusätzlich bietet Redis einen automatischen Failover-Prozess und ermöglicht es, komplexen Code mit weniger und einfacheren Zeilen zu schreiben. Wenn Sie also eine robuste Datenbank für Ihre Aufgaben im Bereich des maschinellen Lernens suchen, dann ist Redis eine optimale Wahl.
Tipp:
Die zahlreichen Varianten hochwertiger Daten, die clickworker bereitstellen kann, sind zugänglich unter
Datensätze für maschinelles Lernen
Ein weiteres außergewöhnliches Open-Source-Datenbanksystem, ist PostgreSQL. Dieses robuste Tool verwendet die SQL-Sprache und verschiedene andere Funktionen, die die komplexesten Daten-Workloads speichern.
Ein herausragendes Merkmal von PostgreSQL ist die Möglichkeit für Entwickler, Anwendungen und Dienste zum Schutz der Datenintegrität zu erstellen. Darüber hinaus gibt es zahlreiche weitere Möglichkeiten, die Sie mit diesem leistungsstarken Datenbanksystem ausprobieren können.
Die Erweiterbarkeit ist ein entscheidendes Merkmal von PostgreSQL, das ihm zu seiner herausragenden Stellung verhilft. Es enthält Fremddaten-Wrapper, die verschiedene Datenbanken oder Datenströme mit einer Standard-SQL-Schnittstelle leicht verbinden können. Darüber hinaus ist PostgreSQL sehr sicher, da es über ein leistungsfähiges Zugriffskontrollsystem verfügt.
Wenn wir über KI-Datenbanken sprechen, dann darf MySQL nicht unerwähnt bleiben. Hinter dieser fantastischen und beliebten Datenbank, die 1995 auf den Markt kam, stehen die Entwickler von Oracle. Viele große Namen in der Tech-Branche nutzen diese Datenbank, z. B. Facebook, Twitter, YouTube usw.
Warum aber ist MySQL so beliebt? Erstens bietet es Enterprise-Grade-Gesten, die es zu einer optimalen Wahl für Unternehmen machen. Zum anderen bietet es eine anpassbare Community-Lizenz, die kostenlos verfügbar ist. Darüber hinaus hat MySQL auch einige Upgrades für seine kommerziellen Lizenzen vorgenommen.
Die Datenbank gewährleistet zudem mehrere Sicherheitsebenen zum Schutz vertraulicher Daten und bietet eine unvergleichliche Skalierbarkeit für große Datenmengen. Ein weiterer Vorteil dieses Datenbanksystems ist die Unterstützung halbstrukturierter Daten (JSON) und strukturierter Daten (SQL). Mit dem MySQL-Cluster ist die Durchführung verschiedener Multi-Master-ACID-Transaktionen möglich.
MongoDB war die erste Dokumentendatenbank, die im Jahr 2009 auf den Markt kam. Das Hauptziel von MongoDB ist die Verwaltung von Dokumentendaten, wobei in den letzten Jahren eine rapide Verbesserung der Gesamtstruktur stattgefunden hat. MongoDB ist unter anderem die beste und beliebteste Dokumentendatenbank.
Darüber hinaus ist es auch ein führender Name, wenn es um NoSQL-Datenbanken geht. Wenn Sie Probleme beim Speichern halbstrukturierter Daten in der Datenbank haben, dann ist MongoDB die beste Lösung für dieses Problem.
Sie können auch das automatische Sharding von MongoDB für die horizontale Skalierung nutzen. Ein weiterer großer Vorteil dieser Datenbank ist die integrierte Replikation über primäre und sekundäre Knoten.
MLDB steht für Machine Learning Database, eines der besten Open-Source-Systeme auf dem Markt. Das Hauptziel dieses Systems ist es, alle Aufgaben des maschinellen Lernens zu bewältigen.
Dieses System kann für verschiedene Zwecke genutzt werden, z. B. zum Sammeln und Speichern von Daten durch Anweisung von Modellen für maschinelles Lernen. Das herausragende Merkmal der MLDB ist, dass sie im Vergleich zu anderen Datensätzen ziemlich einfach zu verwenden ist. Das liegt in erster Linie daran, dass sie über eine umfassende Implementierung der SQL SELECT-Anweisung verfügt.
Dies bedeutet, dass MLDB die Datensätze wie Tabellen behandelt. Folglich wird es für Datenanalysten, die mit dem bestehenden relationalen Datenbankmanagementsystem (RDBMS) vertraut sind, einfacher, die Datensätze zu verwenden.
Der Microsoft SQL Server ist ebenfalls eine sehr beliebte Datenbank. Sie können dieses robuste relationale Datenbankmanagementsystem (RDBMS) verwenden, um relevante Einblicke in alle Arten von Daten zu erhalten. Die Datenbank wurde in C und C++ geschrieben und ist seit über drei Jahrzehnten auf dem Markt.
Dieses leistungsstarke Multi-Modell-System bietet Unterstützung für strukturierte und halbstrukturierte Daten sowie die Verarbeitung räumlicher Daten. Außerdem unterstützt der Microsoft SQL Server serverseitiges Scripting über verschiedene Programmiersprachen wie Python, Java usw.
Zu guter Letzt haben wir noch Apache Cassandra auf unserer Liste. Es ist eine der beliebtesten und besten Datenbanken für maschinelles Lernen und KI auf dem Markt. Dieses skalierbare NoSQL -Datenbankmanagementsystem ermöglicht es Ihnen, größere Datenmengen schnell zu skalieren.
Diese Datenbank wird sogar von beliebten Tech-Unternehmen und Social-Media-Seiten wie Reddit, Instagram und Netflix verwendet. Das herausragende Merkmal dieser Datenbank ist, dass sich die darin enthaltenen Daten zur Fehlertoleranz auf verschiedene Knoten replizieren. Außerdem ist diese Datenbank auf einen hohen Lese- und Schreibdurchsatz ausgelegt. Folglich steigt der Durchsatz linear an, wenn Sie neue Rechner hinzufügen.
Unternehmen, die neue technologische Trends schnell aufgreifen, haben bessere Chancen, sich einen Wettbewerbsvorteil gegenüber anderen zu verschaffen. Daher ist es am besten, sich für eine benutzerdefinierte Datenbank zu entscheiden, da sie Ihnen eine ganze Reihe von Vorteilen bietet. Lassen Sie uns einige davon näher betrachten.
Ein großer Vorteil einer benutzerdefinierten Datenbank ist, dass Sie Ihre Daten schnell verwalten können. Sie können sie für die Berichterstattung, die Erstellung von Arbeitsabläufen, die Automatisierung von Warnmeldungen und vieles mehr nutzen. Da in dieser digitalen Welt alles mit Daten zu tun hat, ist es wichtig, dass Sie sie richtig verwalten.
Darüber hinaus können Sie sicherstellen, dass Ihr Team die Datenbank leicht versteht und sie für Ihre Aufgaben im Bereich des maschinellen Lernens nutzen kann. Dies wird Ihnen helfen, optimale Ergebnisse zu erzielen.
Wenn Sie an einer Aufgabe des maschinellen Lernens arbeiten, ist Geschwindigkeit entscheidend. Kostenlose Datenbanken neigen oft dazu, langsamer zu sein und erfordern unterschiedliche Arbeitsabläufe. Im Gegensatz dazu erhalten Sie durch den Aufbau einer benutzerdefinierten Datenbank ein schlankes System, das Ihre IT-Infrastruktur nicht belastet.
Die Datenbank wird benutzerfreundlich gestaltet, um Ihnen und Ihrem Team eine problemlose Nutzung zu ermöglichen. Sie können die Daten schnell eingeben oder die Datenbank ohne großen Aufwand für unterschiedliche Anforderungen nutzen. Vor allem aber unterstützt sie Ihr Unternehmenswachstum, da die richtige Lösung ohne zusätzlichen Aufwand skaliert werden kann.
Die meisten Menschen entscheiden sich für kostenlose Datenbanken, da sie diese für eine kostengünstigere Option halten. Es mag Sie jedoch überraschen, dass die Verwendung einer benutzerdefinierten Datenbank auf lange Sicht weniger kostet.
Wenn wir über die Einführung neuer Technologien sprechen, geht es nicht nur um die Kosten für die Anschaffung, sondern auch um die Änderungen, die Sie an der Infrastruktur vornehmen müssen, um sie zu nutzen. Auch die Zeit, die Ihre Ressourcen für diese Technologie aufwenden, ist ein Kostenfaktor, den viele Menschen nicht berücksichtigen.
Daher mag es auf den ersten Blick so aussehen, als ob die Verwendung einer kostenlosen Datenbank weniger kostet, aber wenn man genauer hinsieht, wird es auf lange Sicht teuer für Sie. Bei angepassten Datenbanken müssen Sie keine Änderungen an Ihrem IT-System und Ihrer Infrastruktur vornehmen. Und da sie einfach zu bedienen sind, wird Ihr Team nicht viel Zeit damit verbringen, zu verstehen, wie man das Beste daraus macht.
Da Datenbanken für Ihre Aufgaben im Bereich des maschinellen Lernens von entscheidender Bedeutung sind, kann jedes Problem in ihnen das gesamte Projekt zum Stillstand bringen. Das kann Ihre Zeit und Ihre Ressourcen verschwenden, da Sie nicht in der Lage sind, weiterzumachen, wenn die Datenbank nicht korrekt funktioniert. Dieses Problem wird wahrscheinlich auftreten, wenn Sie eine kostenlose Datenbank verwenden.
Das Fehlen eines Kundensupports oder eines technischen Teams kann die Schwierigkeiten weiter verstärken, wenn Probleme mit der Datenbank auftreten. Im Gegensatz dazu bieten Anbieter von benutzerdefinierten Datenbanken nicht nur eine stabilere Lösung von Anfang an, sondern auch fortlaufende technische Unterstützung.
Dienstleister für Datenbankentwicklung wollen sicherstellen, dass ihre Kunden von vornherein eine stabile und fehlerfreie Datenbank erhalten. Sie stehen bereit, technische Expertise zu liefern und bei jeglichen Unklarheiten oder Problemen zu helfen, was einen bedeutenden Vorteil einer maßgeschneiderten Datenbank darstellt.
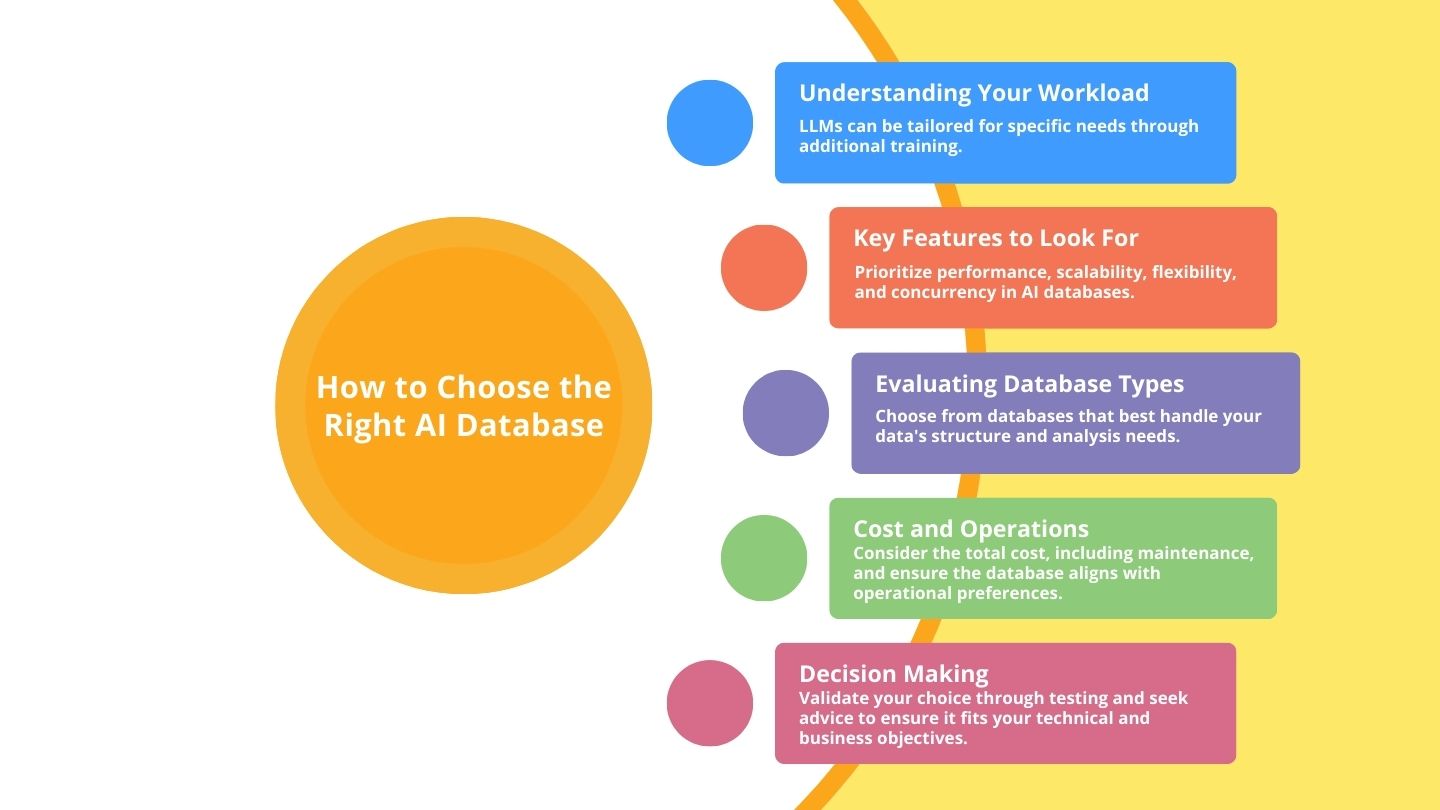
Bei der Auswahl der richtigen KI-Datenbank für Ihre Bedürfnisse müssen Sie Ihre spezifischen Anforderungen, das geplante Datenwachstum und die Art der Analysen, die Sie durchführen möchten, sorgfältig berücksichtigen. Im Folgenden finden Sie einen strukturierten Ansatz, der Sie bei diesem Entscheidungsprozess unterstützt.
Bevor Sie sich mit den Funktionen und Typen von Datenbanken befassen, müssen Sie sich ein klares Bild von Ihren Daten machen. Das bedeutet, dass Sie sich die Art der Daten ansehen müssen, mit denen Sie zu tun haben, z. B. Text, Bilder oder Videos. Überlegen Sie, mit wie vielen Daten Sie arbeiten werden und in welcher Geschwindigkeit diese eingehen werden. Auch die Komplexität der Analyse ist entscheidend. Führen Sie einfache Abfragen durch oder erstellen Sie komplexe maschinelle Lernmodelle? Wenn Sie dies wissen, können Sie besser einschätzen, welche Art von Datenbankfunktionen Sie benötigen.
Leistung und Geschwindigkeit sind bei KI-Datenbanken nicht verhandelbar, da sie sich direkt auf Ihre Fähigkeit auswirken, Daten zeitnah zu verarbeiten. Die Eigenschaft der Datenbank, mit Ihren Daten zu wachsen, die sogenannte Skalierbarkeit, ist ein weiteres wesentliches Merkmal. KI-Anwendungen erfordern oft Flexibilität bei der Datenmodellierung, daher ist eine Datenbank, die verschiedene Datenstrukturen unterstützt, von Vorteil. Parallelität, d. h. die Fähigkeit der Datenbank, mehrere Operationen gleichzeitig zu verarbeiten, ist besonders wichtig für die Datenverarbeitung in Echtzeit.
NoSQL-Datenbanken werden oft bevorzugt, weil sie große Mengen unstrukturierter Daten verwalten können, was bei der künstlichen Intelligenz häufig der Fall ist. NewSQL-Datenbanken vereinen die Skalierbarkeit von NoSQL mit der Zuverlässigkeit herkömmlicher SQL-Datenbanken. Wenn Ihre KI-Anwendungen komplizierte Datenbeziehungen beinhalten, könnte eine Graphdatenbank besser geeignet sein. Für die Analyse von Daten im Zeitverlauf sind möglicherweise Zeitseriendatenbanken erforderlich. Einige KI-Aufgaben, insbesondere solche mit Deep Learning, profitieren von den Hochgeschwindigkeitsverarbeitungsfunktionen GPU-beschleunigter Datenbanken.
Es ist wichtig, nicht nur den Anschaffungspreis zu betrachten, sondern auch die Gesamtbetriebskosten. Dazu gehören auch die langfristigen Ausgaben für Skalierung, Wartung und Support. Es ist auch ratsam, den Support des Anbieters und die Benutzergemeinschaft rund um die Datenbank zu berücksichtigen, da sie unschätzbare Ressourcen darstellen können. Bei Projekten, in denen sensible Daten verarbeitet werden, muss die Datenbank den einschlägigen Sicherheits- und Datenschutzbestimmungen entsprechen. Schließlich ist auch die Benutzerfreundlichkeit wichtig – Ihr Team sollte mit der Datenbank effektiv arbeiten können, ohne dass es eine steile Lernkurve gibt.
Bevor Sie eine endgültige Entscheidung treffen, empfiehlt es sich, einen Machbarkeitsnachweis durchzuführen, um zu sehen, wie die Datenbank mit Ihren Daten und Ihrem Anwendungsfall funktioniert. Benchmarking kann quantitative Daten liefern, um zu vergleichen, wie verschiedene Datenbanken unter bestimmten Bedingungen funktionieren. Und wenn Sie Zweifel haben, sollten Sie sich an Experten wenden. Deren Erfahrung kann Ihnen helfen, eine Datenbank zu finden, die Ihren technischen Anforderungen und Geschäftszielen entspricht.
KI-Datenbanken sind darauf ausgelegt, die Komplexität und die Anforderungen von KI-Arbeitslasten zu bewältigen, die sich erheblich von den Aufgaben unterscheiden, für die herkömmliche Datenbanken in der Regel verwendet werden. Das Verständnis dieser Unterschiede kann helfen zu klären, warum eine spezialisierte KI-Datenbank für bestimmte Anwendungen notwendig sein könnte.
Herkömmliche Datenbanken sind für strukturierte Daten optimiert, die gut in Tabellen passen, wie Finanzdaten oder Kundeninformationen. KI-Datenbanken hingegen sind für eine Vielzahl von Datentypen ausgelegt, darunter auch unstrukturierte Daten wie Bilder, Audio und Text. Sie bieten außerdem flexible Schemata oder sogar eine schemalose Datenverwaltung, um der fluiden Natur von KI-Daten gerecht zu werden.
KI-Anwendungen erfordern häufig eine Datenverarbeitung in Echtzeit und einen hohen Durchsatz, um Modelle zu trainieren und Vorhersagen zu treffen. KI-Datenbanken sind darauf ausgelegt, dieses Leistungsniveau zu liefern. Sie nutzen häufig In-Memory-Verarbeitung, verteilte Architekturen und fortschrittliche Indizierung, um die Datenabfrage und -berechnung zu beschleunigen.
Der Umfang der in der KI verwendeten Daten kann riesig sein und unvorhersehbar wachsen. KI-Datenbanken sind so konzipiert, dass sie sowohl in Bezug auf den Speicherplatz als auch auf die Rechenleistung hoch skalierbar sind, um den Anforderungen umfangreicher maschineller Lernaufgaben gerecht zu werden. Sie bieten die Möglichkeit der Skalierung (Hinzufügen weiterer Knoten) und nicht nur der Skalierung nach oben (Hinzufügen von mehr Leistung zu einem einzelnen Knoten), was eine häufige Einschränkung bei herkömmlichen Datenbanken darstellt.
KI-Datenbanken verfügen häufig über integrierte Analysefunktionen und eine direkte Integration mit Frameworks und Bibliotheken für maschinelles Lernen. Diese Integration vereinfacht die Pipeline von der Datenspeicherung bis zum Modelltraining und zur Inferenzierung. Im Gegensatz dazu müssen bei herkömmlichen Datenbanken die Daten für solche Aufgaben möglicherweise in eine separate Analyseumgebung verschoben werden.
Die meisten Unternehmen, die eine Datenbank für ihre Projekte im Bereich des maschinellen Lernens und der künstlichen Intelligenz nutzen wollen, denken nur an den Kostenaspekt. Sie bedenken nicht die anderen Faktoren, die zu zukünftigen Problemen führen könnten. Hier sind einige Herausforderungen, mit denen Unternehmen, die eine kostenlose Datenbank verwenden, konfrontiert werden können.
Bei der Auswahl der richtigen Datenbanken für Ihr Machine-Learning-Projekt ist die Kompatibilität entscheidend. Wenn Sie diesen Aspekt vernachlässigen, wird das später zu Problemen führen. Die meiste proprietäre Hardware erfordert einen speziellen Treiber, um Open-Source-Datenbanken auszuführen.
Die Gerätehersteller würden Ihnen zwar Zugang zu Datenbanken gewähren, aber für den speziellen Treiber eine Gebühr verlangen. Das kann die Kosten für Ihr Projekt in die Höhe treiben. Selbst wenn Sie einen Open-Source-Treiber haben, ist es sehr wahrscheinlich, dass er mit Ihrer Software nicht funktioniert.
Auch wenn es den Anschein hat, dass die Datenbank kostenlos ist, können später Gebühren anfallen. Die meisten Softwareprogramme sind in der Anfangsphase kostenlos, aber nach einiger Zeit oder für einige zusätzliche Funktionen kann eine geringe Gebühr anfallen. Die Datenbank könnte also zunächst kostenlos sein, aber es werden einige versteckte Kosten anfallen, von denen Sie nichts wissen. Das würde die Kosten für Ihr Projekt wieder erhöhen und den Vorteil einer kostenlosen Datenbank zunichte machen.
Wenn Sie proprietäre Software oder Datenbanken verwenden, sind diese in der Regel mit einer Haftungsfreistellung und einer Garantie seitens der Entwickler verbunden. Diese sind fester Bestandteil der Standard-Lizenzvereinbarung, die Sie von einem Entwickler erhalten. Der Hauptgrund für diese Garantie ist, dass die Entwickler die volle Autorität und das Urheberrecht für das Produkt haben. Bei Open-Source-Softwarelizenzen ist dies jedoch nicht der Fall, da sie nur eine eingeschränkte Garantie und keine Haftung oder Entschädigung beinhalten.
Die Nutzung einer kostenfreien Datenbank könnte für Sie oder Ihr Team unter Umständen mit gewissen Schwierigkeiten verbunden sein. Es besteht die Möglichkeit, dass Sie einen Großteil Ihrer Zeit darauf verwenden, verschiedene Aspekte zu klären, was in dieser digitalen Ära einen kritischen Faktor darstellt. Wenn Ihre Prozesse verlangsamt sind, könnte dies einem Wettbewerber einen Vorteil verschaffen.
Wir hoffen, dass Sie durch diesen Artikel eine umfassende Vorstellung von den Datenbanken für maschinelles Lernen erhalten haben. Daten sind heute eine wichtige Ressource für Unternehmen. Wenn sie richtig genutzt werden, können sich Unternehmen einen Wettbewerbsvorteil gegenüber anderen verschaffen.
Auch die neuen technologischen Konzepte für maschinelles Lernen und künstliche Intelligenz können Ihnen helfen, sich einen Wettbewerbsvorteil gegenüber anderen zu verschaffen. Wenn Sie also die richtigen Datenbanken für Ihre ML-Projekte auswählen können, werden Sie in kürzester Zeit die gewünschten Ergebnisse erzielen.
Eine Datenbank ist eine systematische Sammlung von Daten. Sie kann Bilder, Texte usw. speichern. Mit einer Datenbank können Sie verschiedene Modelle für maschinelles Lernen und künstliche Intelligenz (KI) trainieren.
In DBMS werden die Daten als Datei gespeichert, während in RDBMS die Daten in Form von Tabellen gespeichert werden. MLDB ist ein Beispiel für ein RDBMS.
Die darin enthaltenen Daten werden zur Fehlertoleranz auf verschiedene Knoten repliziert. Außerdem ist diese Datenbank auf einen hohen Lese- und Schreibdurchsatz ausgelegt. Infolgedessen steigt der Durchsatz linear an, wenn Sie neue Maschinen hinzufügen.

