
Es gibt viele Typen und Qualitätsdimensionen von Daten. Diese Eigenschaften tragen zu einem Modell der Künstlichen Intelligenz (KI) bei. Art und Qualität spielen eine große Rolle – aber auch die Vielfalt. Bei den Modellen hängt die Genauigkeit von der Variabilität im Datensatz ab. Je größer die Vielfalt, desto geringer die Verzerrung. Diversität bietet Ihnen mehr Möglichkeiten der Festlegung von Merkmalen in Ihrem Datensatz.
Inhalt
Die Datenqualität bezieht sich auf die Genauigkeit der Daten in einem KI-Modell. Sie ist aus vielen Gründen wichtig, unter anderem zur Bekämpfung von Verzerrungen und zur Minimierung von Fehlern bei einem bestimmten Ergebnis, das möglicherweise durch schlechte Daten verursacht wurden. Die Datenqualität ist auch wichtig, um sicherzustellen, dass das KI-Modell die Daten nicht übermäßig anpasst und somit ein zu ungenaues Ergebnis erzeugt.
Die Qualität der Daten ist entscheidend für den Erfolg von KI-Modellen. Eine schlechte Datenqualität kann zu ungenauen Modellen führen, die in der realen Welt nicht funktionieren. Eine gute Datenqualität hingegen führt zu genaueren und leistungsfähigeren Modellen.
Es gibt eine Reihe von Faktoren, die sich auf die Qualität der Daten auswirken können, wie zum Beispiel:
Jeder dieser Faktoren hat einen großen Einfluss auf die Qualität der Daten und letztlich auch auf die Qualität des KI-Modells.
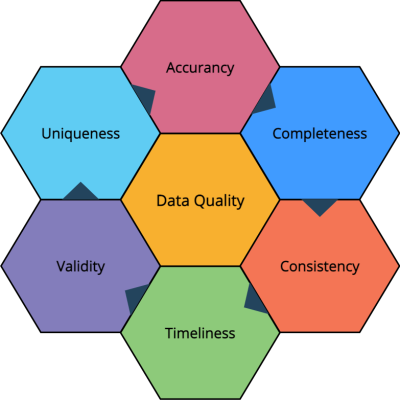
Daten, die genau und aktuell sind, sind mit größerer Wahrscheinlichkeit von hoher Qualität. Die Genauigkeit von Daten in KI-Modellen hängt davon ab, wie gut der Algorithmus Vorhersagen treffen kann und wie exakt er bestimmte Werte vorhersagen kann. Die Genauigkeit der Ergebnisse eines KI-Modells hängt davon ab, was das Modell zu tun versucht und wie es trainiert wurde.
Daten, die vollständig sind und alle erforderlichen Informationen enthalten, sind mit größerer Wahrscheinlichkeit qualitativ hochwertig. Die Vollständigkeit der Daten ist für KI-Modelle sehr wichtig: Sie stellt sicher, dass das Modell über genügend Informationen verfügt, um Vorhersagen zu treffen.
Beispiel: Wenn ein Unternehmen keine Informationen darüber hat, wie seine Kunden ihr Produkt nutzen, kann sein KI-Modell die Präferenzen der Kunden nicht vorhersagen.
Daten, die konsistent und fehlerfrei sind, sind in der Regel von hoher Qualität. Die Konsistenz der Daten ist für KI-Modelle wichtig. Dadurch können sie Entscheidungen auf der Grundlage einer Reihe von Eingaben treffen, die alle miteinander übereinstimmen. Ein gutes Beispiel hierfür wäre ein KI-Modell für den Kundendienst. Wenn die Eingaben konsistent sind, ist auch die Ausgabe zuverlässiger und vorhersehbarer.
Daten, die aktuell sind und die aktuellen Umstände widerspiegeln, sind mit größerer Wahrscheinlichkeit von hoher Qualität. Die Aktualität ermöglicht es den Modellen des maschinellen Lernens, neue Daten aufzunehmen und genauere Vorhersagen zu machen.
Die Datenvalidität gibt an, inwieweit ein Datensatz zuverlässig ist und genaue Informationen liefert.
Die Gültigkeit der Daten ist beim maschinellen Lernen wichtig, denn wenn die Daten nicht gültig sind, werden die Ergebnisse eines Modells falsch sein.
Einzigartige Daten für einen Datensatz sind wichtig, um sicherzustellen, dass beim Training keine Überanpassung stattfindet. Wenn Sie einem Modell zu viele oder falsche Daten beibringen, wird es ein Modell erstellen, das zwar auf die Daten passt, aber nicht richtig verallgemeinert. Einzigartige Daten trennen verschiedene Individuen aus Ihrem Datensatz heraus, damit alle Variationen, die von jedem Individuum ausgehen, vom Modell berücksichtigt werden.
Bei der Datenqualitätskontrolle (Data Quality Control, DQC) geht es darum sicherzustellen, dass die Daten genau, konsistent und vollständig sind. Dieser Prozess zielt darauf ab, die Genauigkeit der von KI-Systemen erfassten Daten zu verbessern. Dies geschieht durch die Erstellung eines Modells, das Ausreißer identifizieren kann.
Datenqualitätssicherung (Data Quality Assurance, DQA) ist der Prozess, mit dem sichergestellt wird, dass die Daten die Anforderungen der Nutzer erfüllen. Bei KI-Datensätzen ist es die Methode, die sicherstellt, dass trainierte Modelle für maschinelles Lernen zuverlässig und genau sind. Um die Datenqualität sicherzustellen, muss zunächst die Genauigkeit eines Modells definiert werden. Diese Genauigkeit ist der Prozentsatz der Fälle, in denen ein Modell bei einer Abfrage ein erwartetes Ergebnis liefert.
Optimierter ROI durch Datenqualität und Datenvielfalt
Datenqualität und Datenvielfalt sind zwei wesentliche Faktoren für die Rentabilität von KI. Hochwertige Daten sind für das Training präziser KI-Modelle unerlässlich, während vielfältige Daten notwendig sind, um Verzerrungen und Überanpassungen zu vermeiden. Wenn Unternehmen sowohl die Datenqualität als auch die Datenvielfalt sicherstellen, können sie ihre KI-Investitionen maximieren und den größten ROI erzielen.
In vielen Branchen ist es sehr schwierig, die notwendigen – und oft speziellen – Ausbildungsdaten zu beschaffen (…). Deshalb brauchen Unternehmen jemanden, der ihnen hilft, die Daten zu beschaffen, die Qualität der Daten zu gewährleisten und sicherzustellen, dass die Daten legal sind– Christian Rozsenich, clickworker CEOWir bieten Ihnen die Möglichkeit, ein ausführliches Whitepaper zum Thema zu erhalten, in dem wir die Bedeutung von Datenqualität und -vielfalt im Hinblick auf das KI-Training näher beleuchten. Darin werden zwei Anwendungsfälle zum Thema Gesichtserkennung und Spracherkennung vorgestellt.
Download Whitepaper
Beim Training von KI-Modellen ist es wichtig, über einen vielfältigen Datensatz zu verfügen, der eine Vielzahl von Datenpunkten enthält. Diese Vielfalt ist aus zwei Gründen wichtig:
Überanpassung ist ein großes Problem. Überangepasste KI-Modelle schneiden immer dann schlecht ab,wenn sie mit Daten getestet werden, die nicht für das Training verwendet wurden.
Ein weiterer Punkt ist der Einfluss der Datenvielfalt auf die Fairness von KI. So ist beispielsweise bekannt, dass viele der am weitesten verbreiteten Algorithmen für maschinelles Lernen Frauen und Minderheiten benachteiligen, weil sie auf Datensätzen mit einer überproportionalen Anzahl von männlichen und weißen Teilnehmern trainiert wurden.
Datenvielfalt ist auch für die Abwehr feindlicher Angriffe nötig. So wird verhindert, dass ein Angreifer ein KI-System dazu zu bringen, eine falsche Entscheidung zu treffen. Wenn ein KI-System beispielsweise mit einem Datensatz trainiert wird, der von einem böswilligen Akteur mit falschen Personendaten manipuliert wurde, kann das Modell dazu verleitet werden, falsche Entscheidungen zu treffen, wenn es in der realen Welt auf diese Personen trifft.
Es gibt mehrere Möglichkeiten, eine Datenvielfalt in KI-Trainingsdatensätzen zu erreichen:
Ohne hochwertige und vielfältige Daten ist es für die KI schwierig, genaue Entscheidungen zu treffen. Datenqualität ist der Schlüssel, um sicherzustellen, dass die von der KI verwendeten Daten zuverlässig und aussagekräftig sind. Indem Sie Ihre Datenquellen standardisieren und diversifizieren, stellen Sie sicher, dass Ihre Modelle in der Lage sind, aus einem breiten Spektrum von Situationen zu lernen. Indem Sie die Genauigkeit Ihrer Trainingsdatensätze gewährleisten, können Sie außerdem die Leistung Ihrer KI-Anwendungen insgesamt verbessern.
Eine Methode zur Bewertung der Datenqualität ist die manuelle Überprüfung. Mit manuellen Überprüfungen kann sichergestellt werden, dass die Daten Spezifikationen wie Vollständigkeit, Konsistenz und Genauigkeit erfüllen. Manuelle Überprüfungen erfordern einen erfahrenen Analysten, der Fehler und Datenlücken erkennen kann.
KI-Modelle benötigen qualitativ hochwertige Daten, um genaue Vorhersagen treffen zu können. Sie ermöglichen es KI-Modellen, das Ergebnis jeder Situation genau vorherzusagen, und erlauben es ihnen außerdem, im Laufe der Zeit weiter zu lernen.
Eine Datenqualitätsdimension ist eine der wichtigsten Dimensionen, die in einem KI-Modell verwendet werden. Ein gutes Beispiel ist die Genauigkeit oder Vertrauenswürdigkeit, die dazu beitragen kann, die Leistungsfähigkeit des Modells zu bestimmen.

