
Synthetische Daten sind auf dem Vormarsch – auch in der Marktforschung. Mithilfe von Algorithmen generiert, sollen sie reale Antworten simulieren und neue Wege für Analysen und Tests eröffnen. Anwendungen reichen von Verhaltenssimulationen über Zielgruppenmodellierungen bis hin zu Tests von Fragebögen. Doch wie zuverlässig sind synthetische Antworten wirklich? Und welche Rolle spielen reale Nutzerdaten in einer Welt, in der künstlich erzeugte Informationen immer verfügbarer werden? Dieser Beitrag beleuchtet die Chancen und Grenzen synthetischer Daten – und zeigt, worauf Marktforscher achten sollten.
Table of Contents
- Key Takeaways: Synthetische Daten vs. reale Nutzerdaten
- Was sind synthetische Daten?
- Wie entstehen synthetische Daten in der Marktforschung?
- Wo liegen die Risiken synthetischer Testdaten?
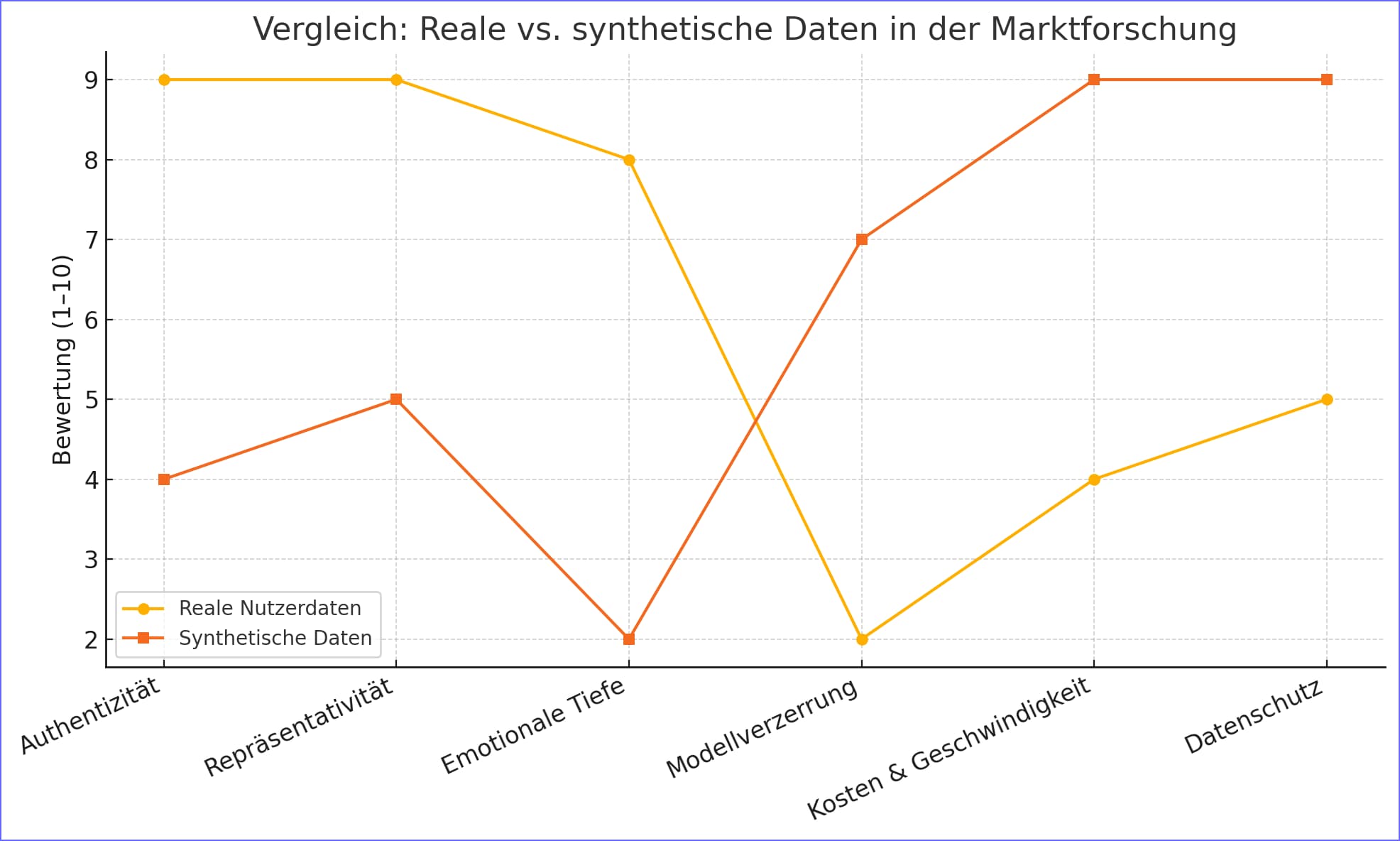
- Warum reale Nutzerdaten überlegen sind
- Praxisbeispiel: Was echte Nutzerbefragungen leisten können
- Fazit: Künstlich ist nicht gleich nützlich
- FAQ
| Aspekt | Details |
|---|---|
| Synthetische Daten | Künstlich erzeugte Datensätze, die reale Antwortmuster nachahmen. Entstehen durch Algorithmen auf Basis bestehender Daten. |
| Einsatzmöglichkeiten | Simulation von Szenarien, Test von Fragebögen, Ergänzung schwer erreichbarer Zielgruppen – mit Vorsicht einsetzbar. |
| Risiken | Fehlende emotionale Tiefe, verzerrte Ergebnisse, geringe Varianz, eingeschränkte Repräsentativität, Intransparenz bei Modellen. |
| Stärken realer Daten | Authentisches Feedback, reale Entscheidungsgrundlagen, höhere Glaubwürdigkeit, bessere Rückschlüsse auf Zielgruppen. |
| Praxisnutzen | Nur echte Nutzer können relevante Rückmeldungen zu Sprache, Design, Nutzen oder Positionierung geben. |
| Empfehlung | Synthetische Daten können vorbereitend eingesetzt werden – für valide Ergebnisse braucht es aber echte Nutzerbefragungen. |
Synthetische Daten sind künstlich erzeugte Informationen, die reale Datensätze nachahmen sollen. In der Marktforschung bedeutet das: Antworten, Nutzerprofile oder Verhaltensmuster werden mithilfe von Algorithmen generiert, ohne dass sie jemals von echten Personen stammen.
Im Unterschied zu anonymisierten Daten, bei denen reale Nutzerinformationen lediglich unkenntlich gemacht werden, basieren synthetische Datensätze vollständig auf Modellen. Sie entstehen häufig durch maschinelles Lernen, das statistische Muster aus vorhandenen echten Daten erkennt und daraus neue, künstliche Datensätze erstellt.
Anwendungsbereiche für synthetische Daten sind vielfältig. Dazu zählen etwa die Simulation von Nutzerverhalten, die Modellierung neuer Zielgruppen oder das Testen von Umfrage-Designs vor dem realen Feldeinsatz. Besonders in Bereichen, in denen Datenschutzanforderungen hoch sind oder schwer erreichbare Zielgruppen erforscht werden sollen, erscheinen synthetische Daten auf den ersten Blick attraktiv.
Doch auch wenn sie reale Muster imitieren können, fehlt synthetischen Datensätzen eine wichtige Dimension: der authentische Ursprung aus echten Erfahrungen, Präferenzen und Emotionen.
In der Marktforschung werden synthetische Daten meist auf Basis realer Datensätze erzeugt. Mithilfe von Machine-Learning-Modellen oder regelbasierten Algorithmen analysieren Systeme vorhandene Antwortmuster, Korrelationen und demografische Strukturen. Daraus leiten sie neue, künstliche „Antworten“ ab, die statistisch plausibel, aber nicht real sind.
Dabei kommen unterschiedliche Verfahren zum Einsatz – von einfachen Regressionsmodellen bis hin zu komplexen generativen Modellen wie GANs (Generative Adversarial Networks). Diese Modelle lernen, wie typische Teilnehmer auf bestimmte Fragen reagieren würden, und erstellen daraus künstliche Datensätze, die „echt“ wirken sollen.
In der Praxis werden solche synthetischen Antworten verwendet, um beispielsweise:
Doch auch wenn diese Ansätze in bestimmten Situationen methodisch hilfreich sein können: Sie basieren nicht auf tatsächlichem Verhalten realer Personen. Jede synthetische Antwort ist ein Produkt von Annahmen – und genau das birgt Risiken für die Validität der Ergebnisse.
Erreichen Sie echte Zielgruppen mit clickworker
Verlassen Sie sich auf echte Nutzerdaten statt auf Modellannahmen. Mit clickworker befragen Sie genau die Zielgruppen, die für Ihre Fragestellungen relevant sind – schnell, DSGVO-konform und präzise steuerbar. Unser Teilnehmernetzwerk ermöglicht belastbare Marktforschung auf Basis authentischer Meinungen und echter Nutzererfahrungen.
Mehr über unsere Umfrageteilnehmer erfahren
Synthetische Daten mögen auf den ersten Blick effizient und vielseitig erscheinen, doch bei näherer Betrachtung zeigen sich deutliche Schwächen. Vor allem dann, wenn sie als Ersatz für echte Nutzermeinungen verwendet werden, können sie zu falschen Schlussfolgerungen führen.
Reale Nutzerdaten bilden die Grundlage jeder fundierten Marktforschung. Sie beruhen auf echten Erfahrungen, konkreten Meinungen und realen Lebenssituationen – und liefern dadurch Erkenntnisse, die in ihrer Tiefe und Relevanz von synthetischen Daten nicht erreicht werden können.
Ein mittelständisches Unternehmen im Bereich Haushaltswaren wollte ein neues, nachhaltiges Reinigungsprodukt einführen. Die erste Konzeptbewertung wurde mithilfe eines KI-basierten Simulationsmodells durchgeführt: Die synthetischen Antworten deuteten auf hohe Akzeptanz und ein positives Preis-Leistungs-Verhältnis hin. Die Markteinführung wurde vorbereitet – auf Basis dieser Daten.
Bevor das Produkt final freigegeben wurde, entschied sich das Team dennoch für eine kurze Nutzerbefragung mit echten Personen aus der relevanten Zielgruppe. Das Ergebnis: Eine Vielzahl der realen Befragten zeigte deutliche Zweifel an der Wirksamkeit des Produkts. Viele fanden die Produktbeschreibung unverständlich, die Verpackung als unpraktisch – Punkte, die im synthetischen Datensatz nicht auftauchten.
Auf Basis dieser realen Rückmeldungen wurde das Produkt angepasst: klarere Kommunikation, geänderte Verpackung, überarbeitete Preispositionierung. Der spätere Markteintritt verlief deutlich erfolgreicher als ursprünglich geplant.
Dieses Beispiel zeigt: Synthetische Daten können erste Hypothesen generieren – doch echte Nutzer liefern das entscheidende Feedback, um Fehlentscheidungen zu vermeiden und Produkte marktgerecht weiterzuentwickeln.
Synthetische Daten bieten zweifellos neue Möglichkeiten für bestimmte Anwendungsbereiche in der Marktforschung – etwa beim Testen von Fragebögen, beim Schließen von Datenlücken oder in datenschutzsensiblen Kontexten. Doch sobald es darum geht, echte Einstellungen, Emotionen oder Reaktionen zu erfassen, stoßen sie an klare Grenzen.
Wer fundierte Entscheidungen treffen will, braucht nachvollziehbare, belastbare und vor allem reale Nutzermeinungen. Nur sie spiegeln die tatsächliche Komplexität von Zielgruppen wider – mit all ihren Widersprüchen, individuellen Motiven und spontanen Reaktionen. Für Marktforscher bleibt daher klar: KI-generierte Antworten können punktuell unterstützen, aber sie ersetzen nicht den direkten Kontakt zu echten Menschen.
Synthetische Daten sind künstlich erzeugte Datensätze, die mithilfe von Algorithmen reale Antwortmuster nachahmen. In der Marktforschung handelt es sich dabei um simulierte Antworten, Nutzerprofile oder Verhaltensdaten – nicht um Informationen, die von echten Menschen stammen. Sie basieren auf statistischen Modellen, die auf vorhandenen Realdaten trainiert wurden.
Synthetische Daten eignen sich für bestimmte vorbereitende Zwecke: etwa zum Testen von Fragebogenlogiken vor dem Feldeinsatz, zum Auffüllen von Datenlücken bei schwer erreichbaren Zielgruppen oder für What-if-Szenarioanalysen. Als Ersatz für echte Nutzerbefragungen sind sie jedoch nicht geeignet, sobald valide und entscheidungsrelevante Ergebnisse gefragt sind.
Zu den größten Risiken zählen Verzerrungen durch fehlerhafte Trainingsdaten, fehlende emotionale Tiefe, künstliche Antworthomogenität und eingeschränkte Repräsentativität. Vor allem können synthetische Daten reale Motivationen, kulturelle Nuancen oder spontane Reaktionen nicht abbilden – was zu strategischen Fehleinschätzungen führen kann.
Echte Nutzerdaten spiegeln authentisches Verhalten, individuelle Erfahrungen und die tatsächliche Vielfalt von Zielgruppen wider. Sie sind nachvollziehbar, methodisch belastbar und genießen bei Stakeholdern deutlich mehr Vertrauen. Anders als synthetische Daten erfassen sie unerwartete Reaktionen und emotionale Nuancen – beides entscheidend für fundierte Entscheidungen.
Ja, eine ergänzende Nutzung ist möglich. Synthetische Daten können in frühen Phasen bei der Hypothesengenerierung oder beim Fragebogentest unterstützen, während echte Nutzerbefragungen die validen, handlungsrelevanten Erkenntnisse für finale Entscheidungen liefern. Synthetische Daten sollten jedoch niemals als vollständiger Ersatz für echtes Nutzerfeedback dienen.
Schreibe einen Kommentar

